Sara Diamond (Principal Investigator)
Juliette Dennis (Advisor)
Silvana N. Sari (Design Researcher & Graphic Designer)
Michael Li (Design Researcher & UI Designer)
Juan Sulca (Developer)
The Canadian Cultural Data Catalogue (CCDC) is a national discovery platform designed to standardize and surface cultural datasets across Canada. Developed from the ground up, the project involved designing a scalable metadata schema, building a flexible cultural taxonomy, and translating both into a searchable, production-ready digital platform.


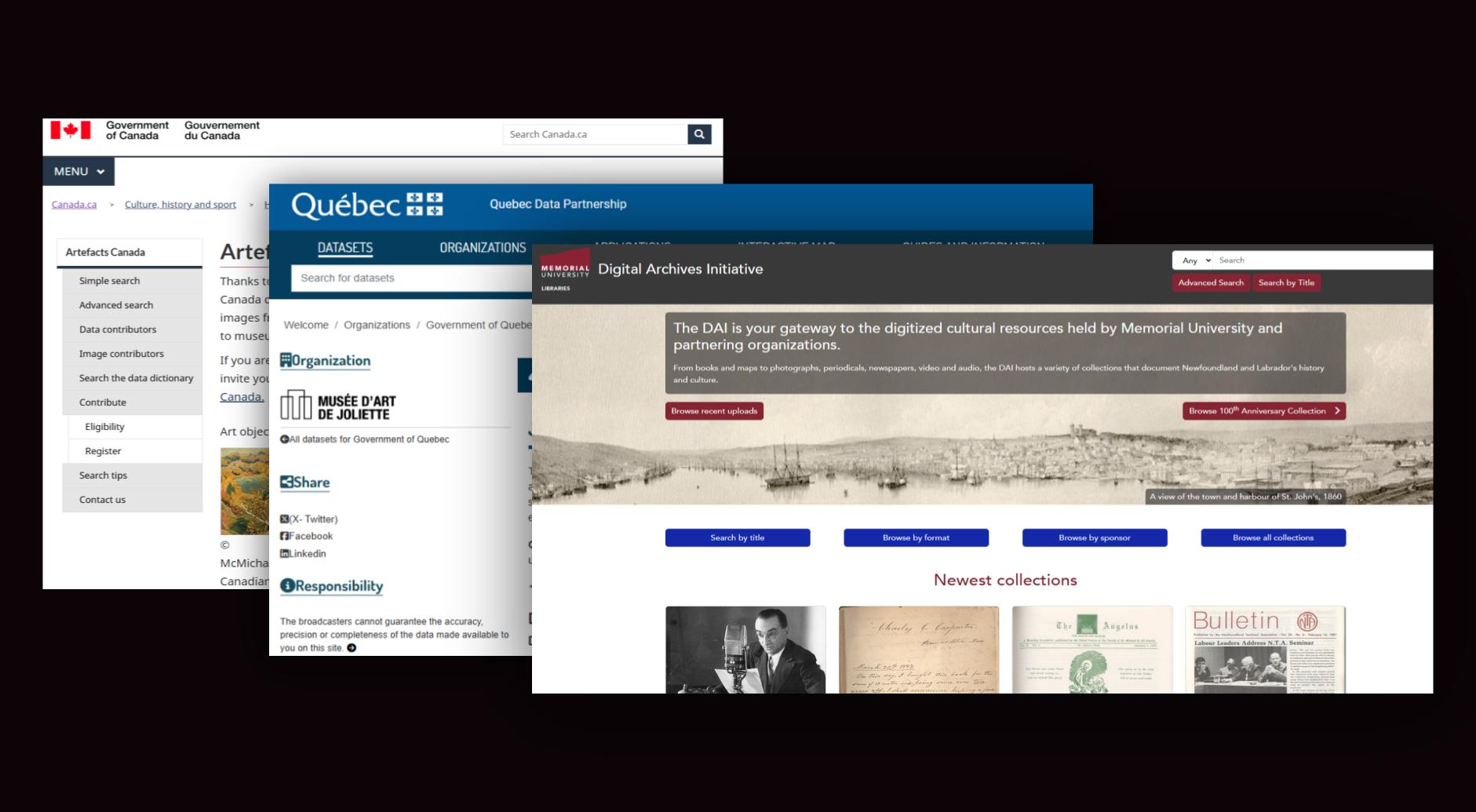
Cultural data in Canada is distributed across government agencies, research institutions, arts councils, and independent organizations. However, the ecosystem lacked a centralized mechanism to:
For researchers, policymakers, and arts organizations, locating relevant datasets required extensive manual searching across disconnected sources.
This presented a structural problem: not an absence of data, but an absence of organized, searchable infrastructure. Thus, the objective of this project was to design and launch a national catalogue that would make cultural datasets discoverable, structured, and scalable.
The objectives of Building a Data Fluent Canadian Cultural Sector are to discover and strengthen Canada’s current cultural analytics capacity by setting the groundwork for unified initiatives in data collection and analysis by the Canadian cultural sector; identifying academic, public sector and industry researchers undertaking cultural analytics; coordinating significant and ongoing engagement to lead to future research and establish a shared database. The project aims to:
The first part of this project consists of the following:
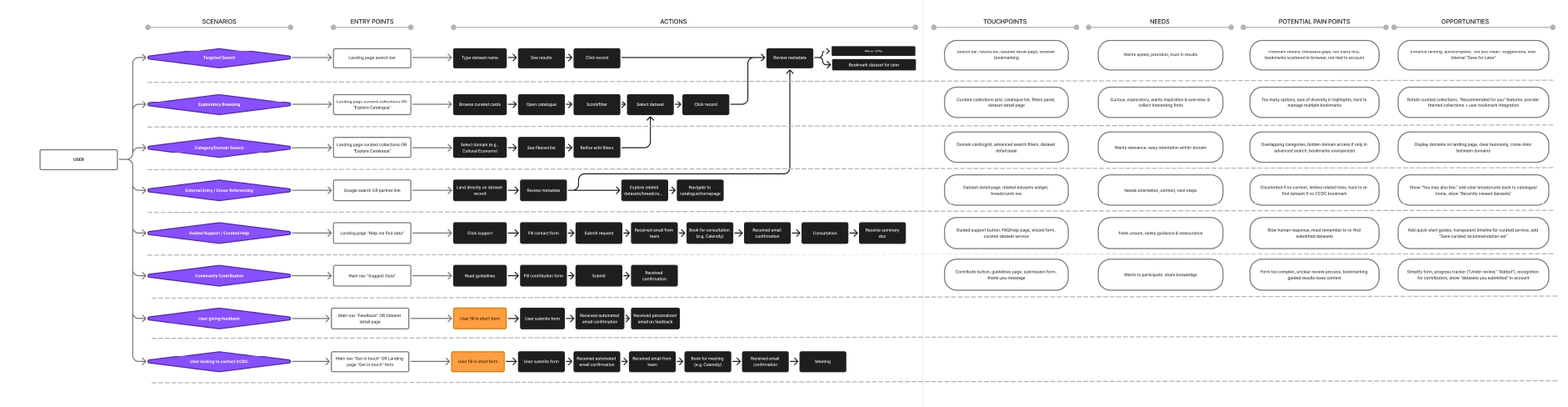
After the initial landscape scan and the prototype “database of databases” concept, the next step was to clarify who the platform was for and what a “successful search experience” would look like in practice. We moved from inventory-building to experience definition by consolidating signals from three sources:
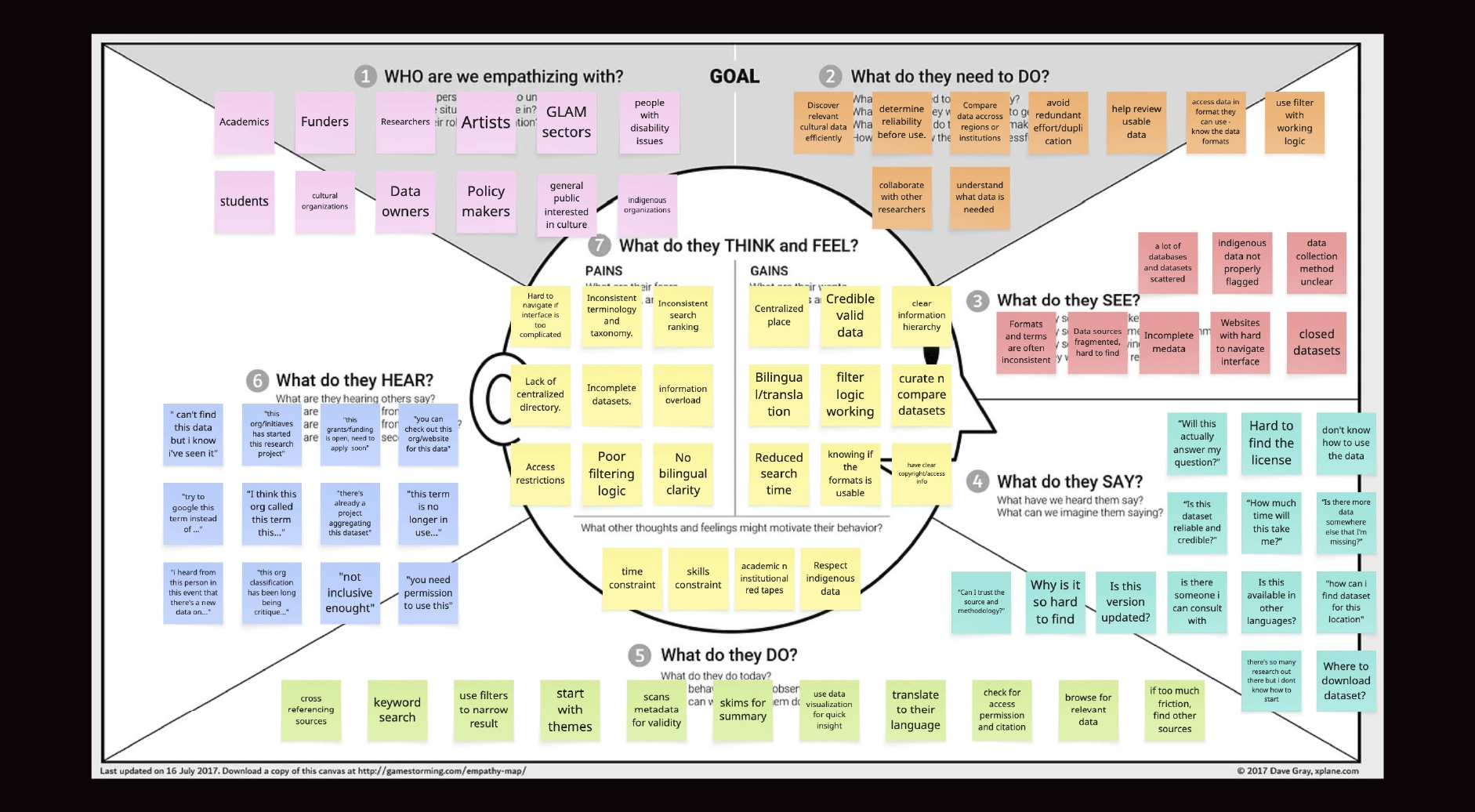
The empathy mapping directly informed platform requirements, including:
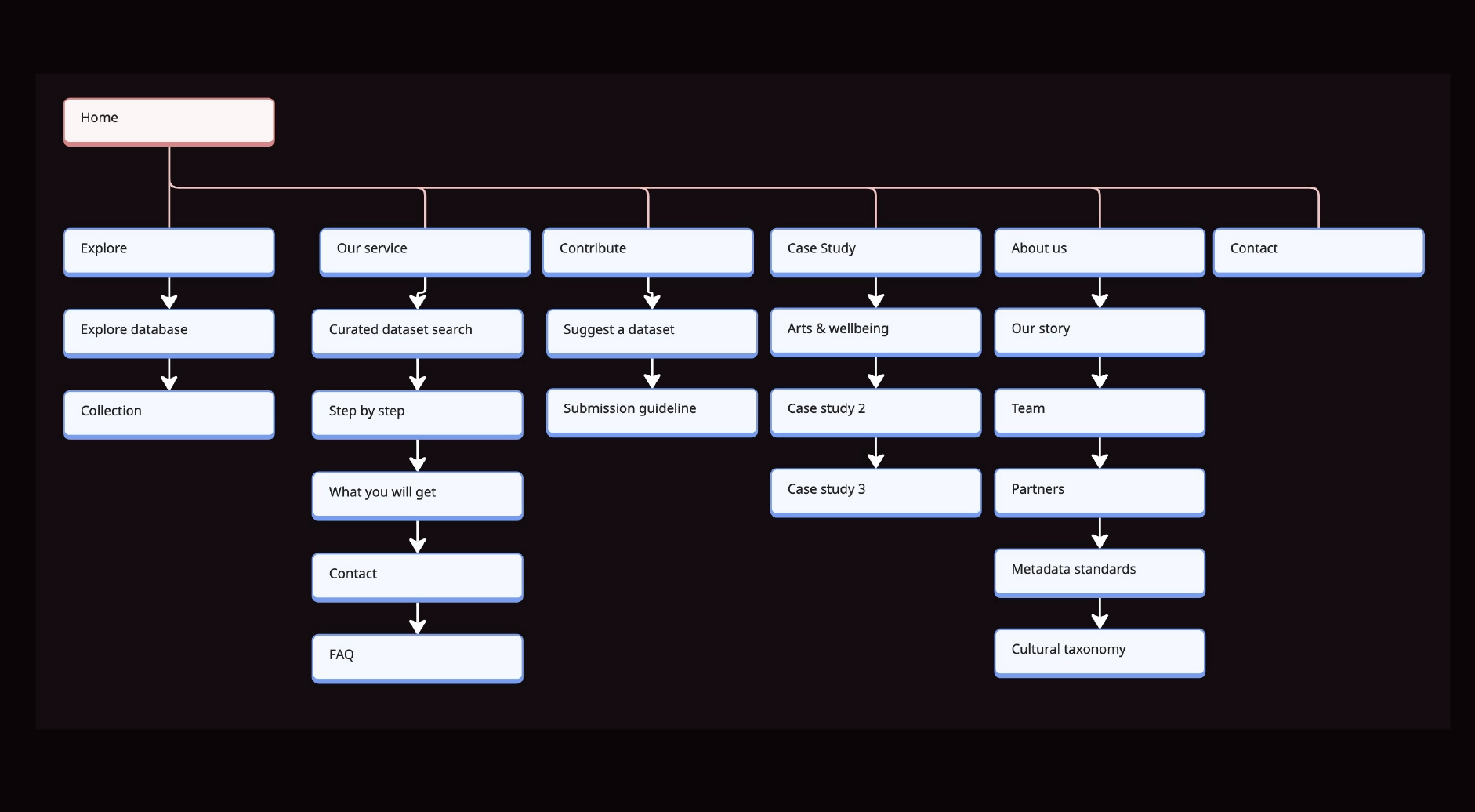
This became the bridge between the research inventory work and experience design decisions, shaping how datasets are represented, filtered, and understood in the catalogue.
The first iteration of the product was not a digital interface but a structured metadata framework. Using the School of Cities Metadata Maturity paper by our colleagues in University of Toronto as the foundation, we developed a standardized schema defining:
.jpg)
To validate the model, we initially manually catalogued real datasets in a structured Excel environment. This approach functioned as:
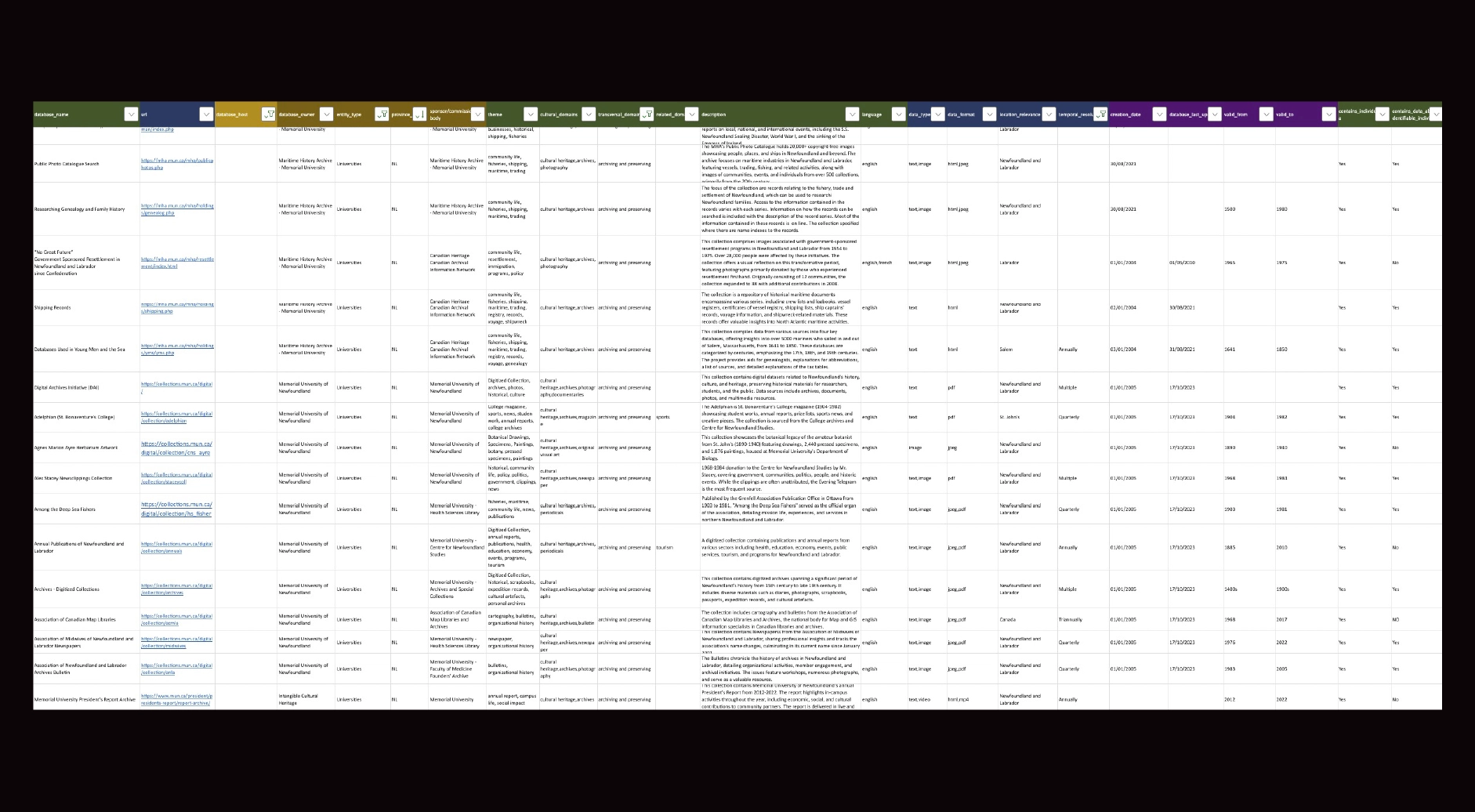
As the number of catalogued datasets grew, classification complexity increased significantly. Cultural practices frequently overlap across domains, and disciplinary boundaries are rarely fixed. We referenced established Canadian cultural taxonomies as a foundation, given that many data-producing organizations and funding bodies align with these standards. This ensured interoperability across institutions.
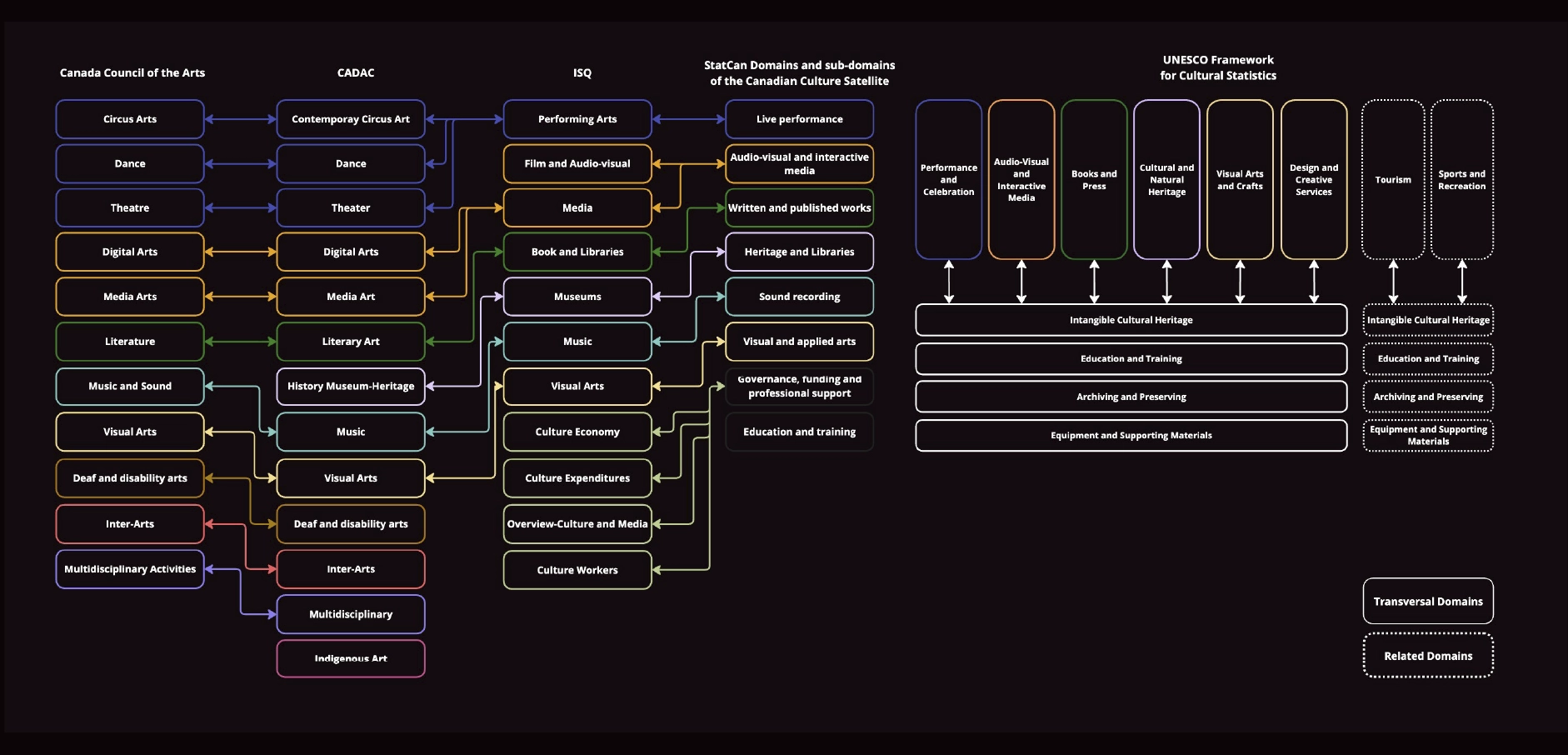
However, we recognized that existing taxonomies are not exhaustive and may not fully reflect the diversity and evolution of cultural practices in Canada. A rigid, single-hierarchy model would have constrained discoverability and reduced accuracy. To address this, we designed a flexible, polyhierarchical structure complemented by a thematic layer that functions similarly to a controlled folksonomy. This allows for more granular tagging and the inclusion of emerging or cross-disciplinary practices, while maintaining governance oversight to ensure consistency and scalability.
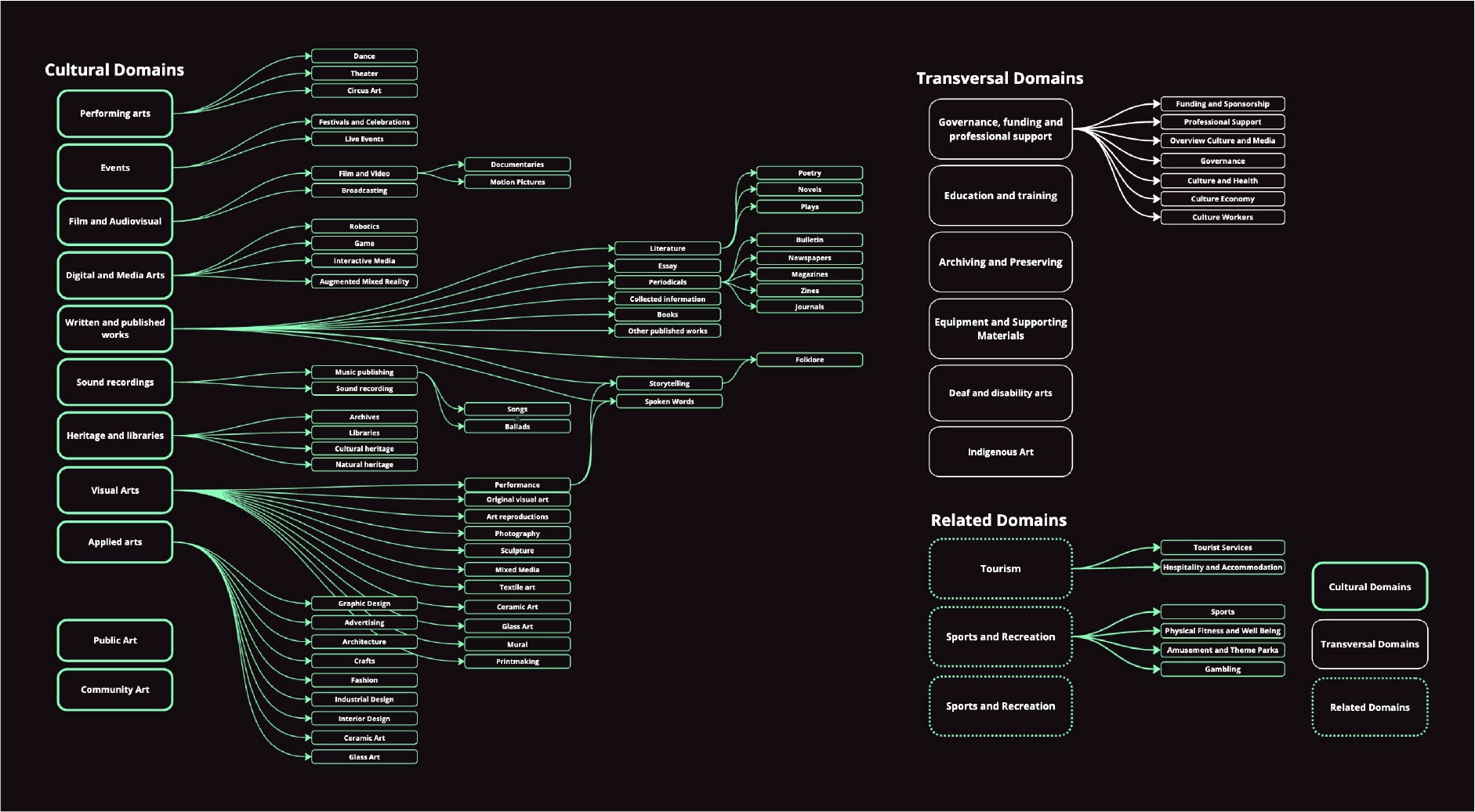
This structure enabled:
The taxonomy directly informed:
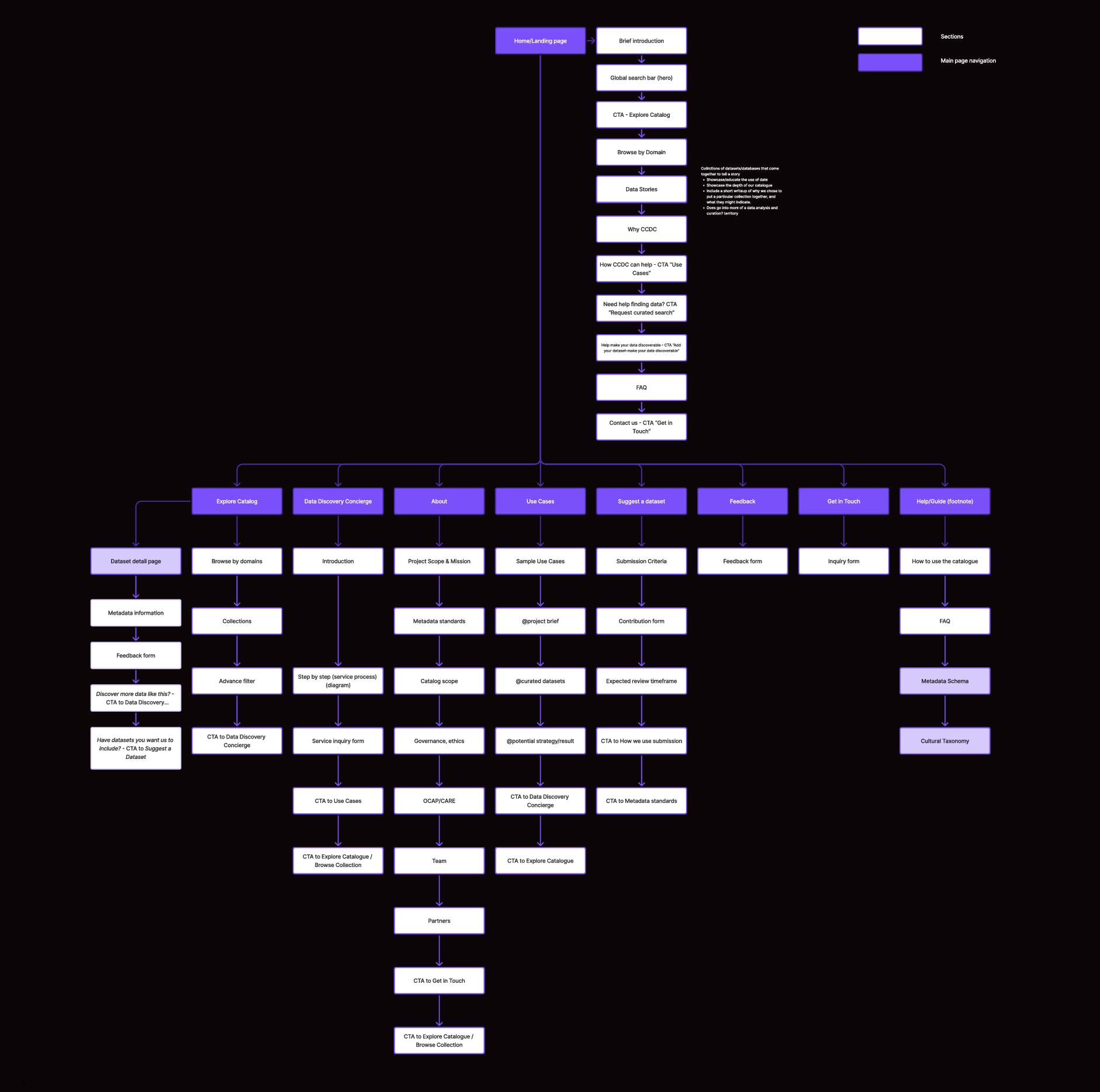
Before interface design, we conducted qualitative research across comparable data discovery platforms to evaluate information hierarchy, search behaviour, and metadata prioritization patterns. These findings were combined with insights from interest holders interviews, including researchers, arts administrators, and policymakers, and sector expertise from our Principal Investigator, Sara Diamond.
This synthesis directly informed the platform’s information architecture and service structure.
We defined clear prioritization rules for:


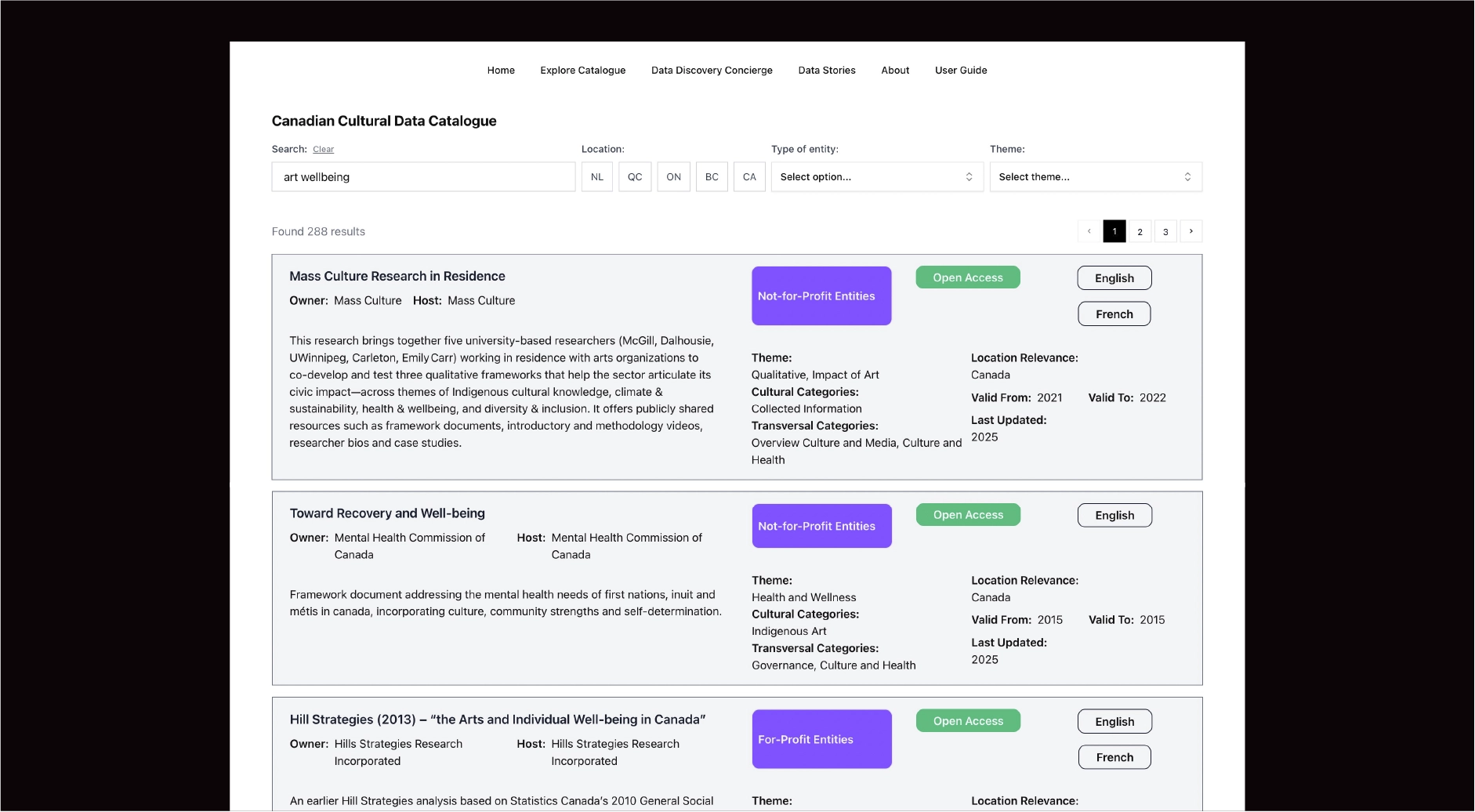
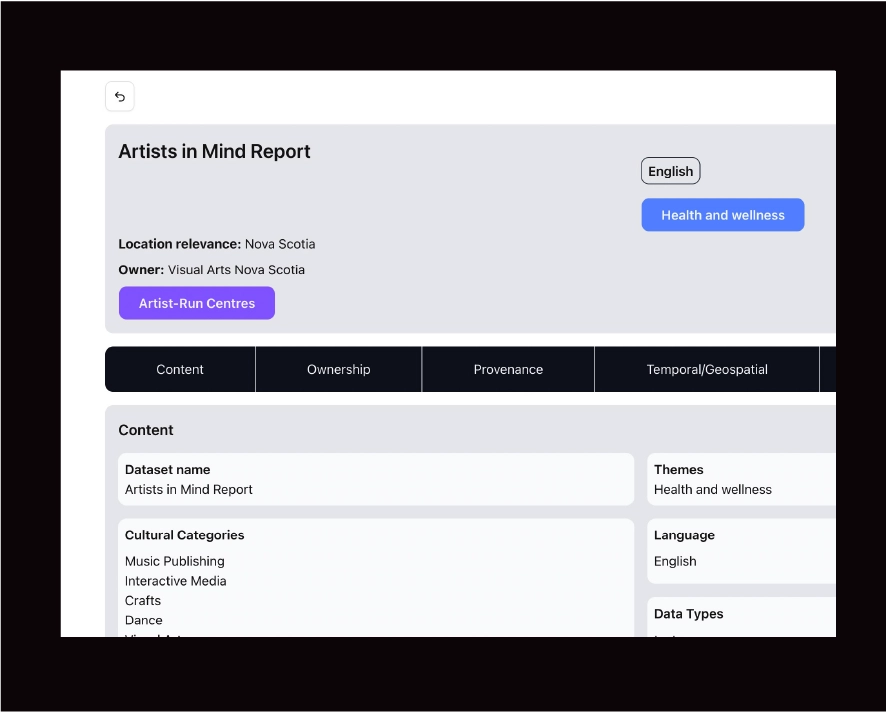
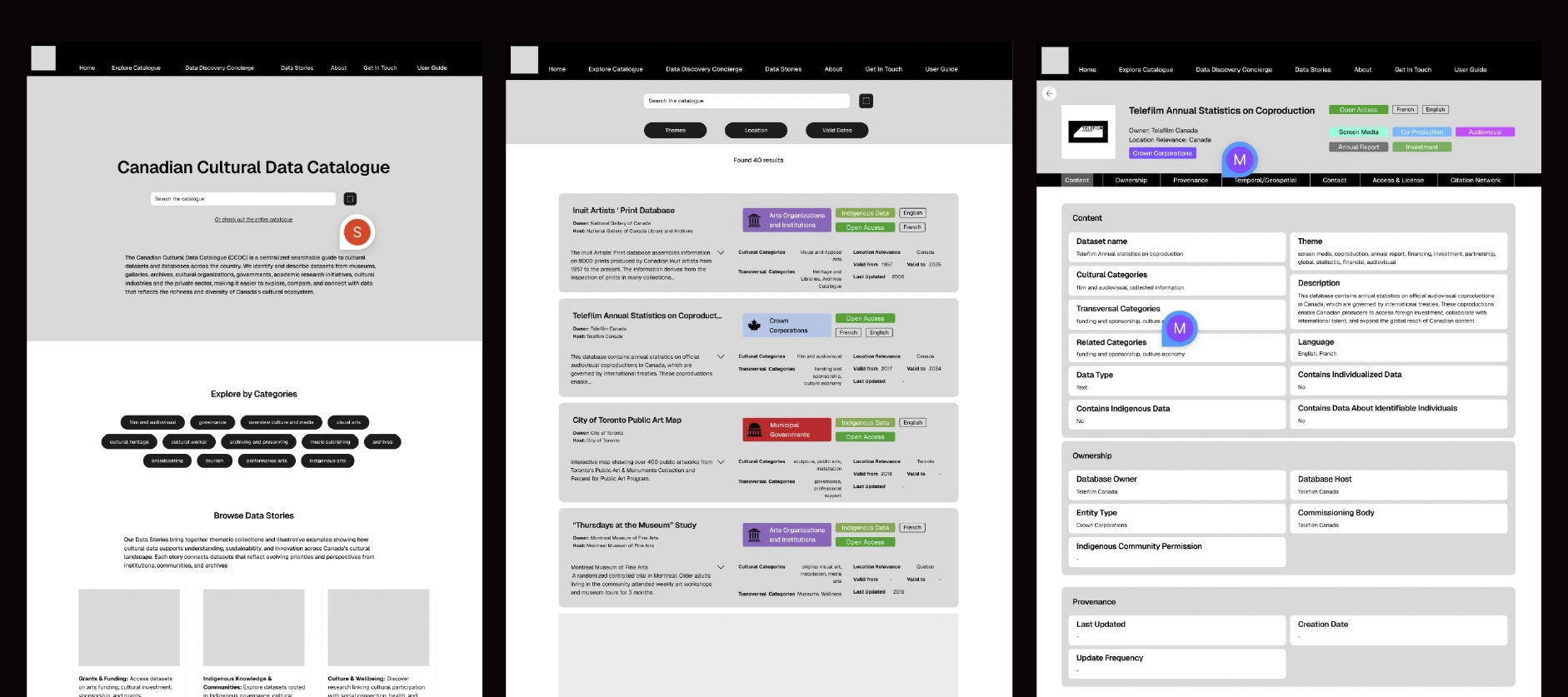
Search results were designed to surface essential metadata such as provider, geographic scope, thematic classification, temporal coverage, and access status, allowing rapid assessment. Detail pages were organized into structured categories (content, provenance, governance, temporal/geospatial) to support deeper evaluation.
Personas were developed from interest holder research to reflect varying levels of data literacy and discovery intent. The service blueprint mapped:
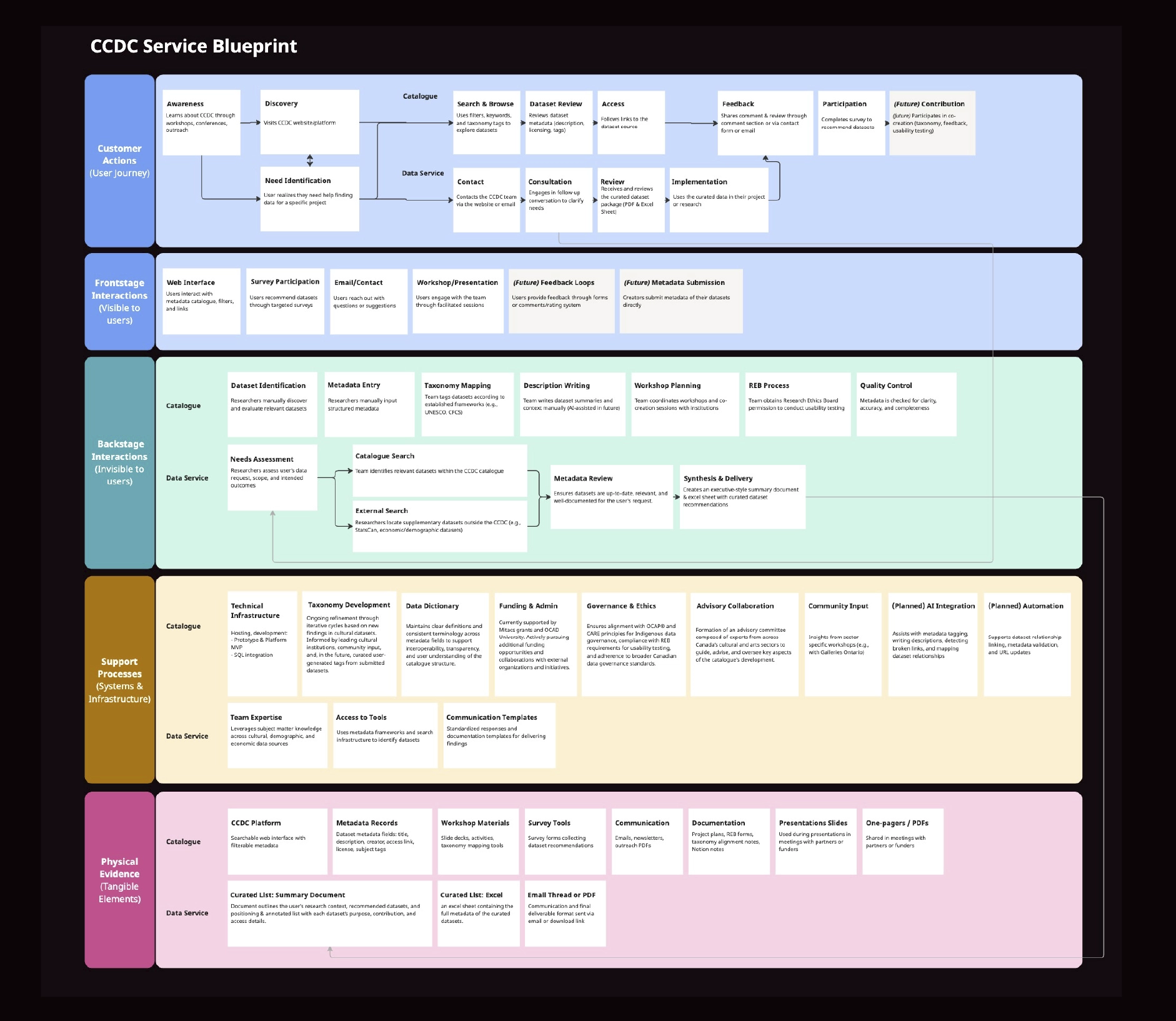
This clarified operational dependencies early, reducing implementation risk and preventing governance bottlenecks.
The interface was intentionally search-forward and structurally disciplined, featuring:
Design emphasis was placed on clarity, comparability, and trust, ensuring the data remained central to the experience.
Once the information hierarchy and high-fidelity prototype were finalized, we transitioned from conceptual design to technical execution.
.jpg)
The first critical step was converting the metadata schema into a relational SQL database model. SQL was selected to ensure:
Because our engineer joined mid-project, we worked closely to align taxonomy concepts with database constraints. This collaboration surfaced early misconceptions in our conceptual model and allowed us to refine field relationships, reduce redundancy, and optimize for search performance before full implementation.
The taxonomy, transversal domains, and thematic layers were translated into queryable logic. This required iterative cycles of:
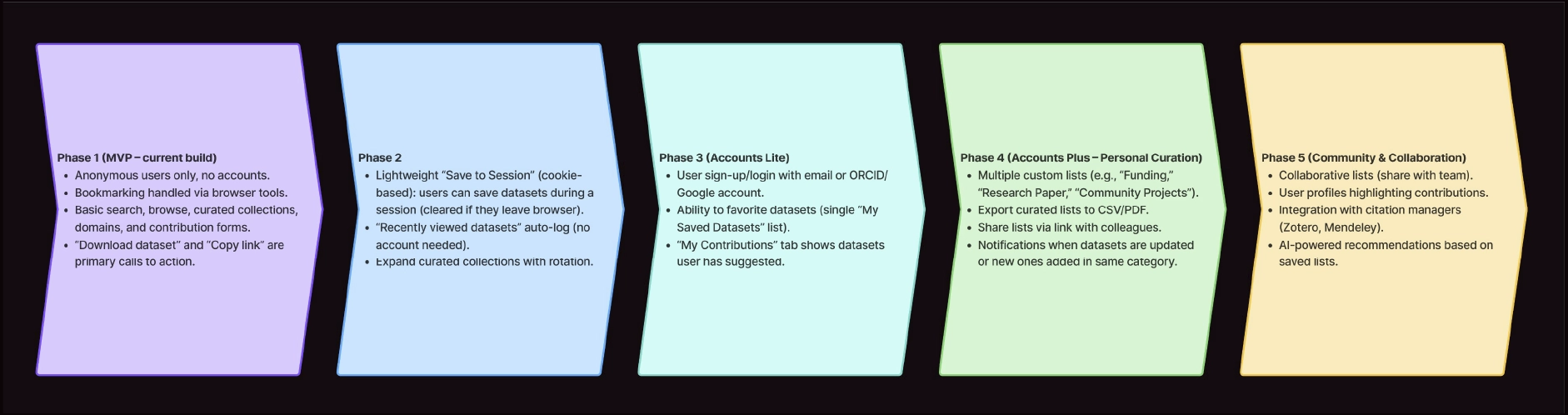
A phased roadmap defined feature sequencing and launch readiness criteria. For the initial release, we prioritized:
Advanced features were intentionally deferred to maintain delivery discipline.
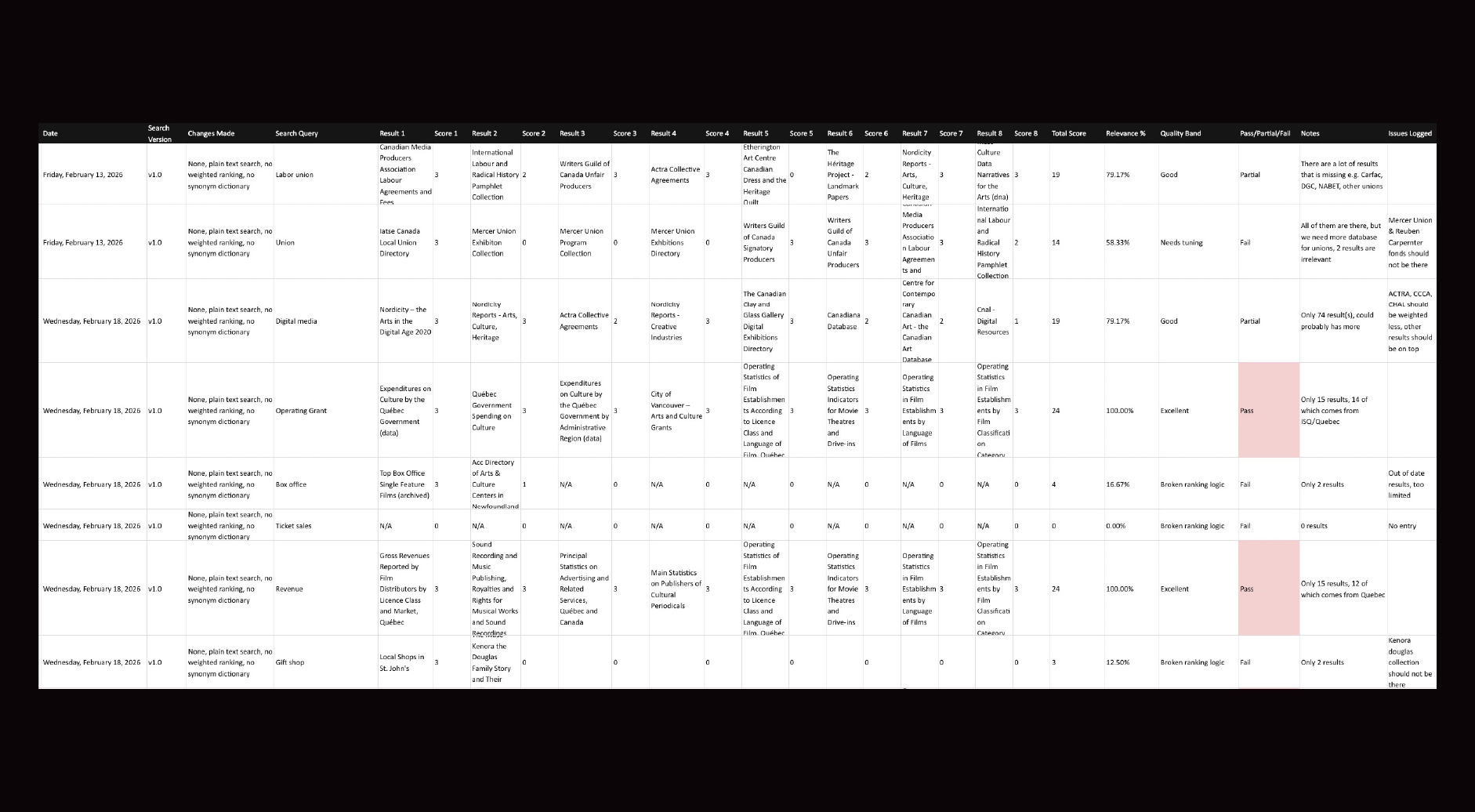
Before launch, we conducted structured testing cycles to validate:
The high-fidelity prototype was translated into production through close collaboration between design and engineering, with multiple pre-launch test runs conducted in preparation for live demonstration.
The platform was publicly launched at the Mass Culture Digital National Assembly (DNA) Expo.


Attendance exceeded expectations, with close to 100 participants joining the session. Following a brief presentation outlining the project’s objectives, methodology, and roadmap, participants were invited to actively explore the platform in real time. We were transparent that this was the first large-scale public use of the online product and positioned the session as a live testing environment.
While the search logic did not perform flawlessly in every instance, participants were informed in advance that they were contributing to an early-stage validation process. This transparency fostered constructive engagement rather than hesitation.
The session yielded several tangible outcomes:
The launch served not only as a release milestone but as a live stress test under real user conditions. It validated the platform’s core architecture while providing actionable insights for refinement and iteration.
Throughout development, several strategic trade-offs shaped the platform’s direction.
1. Standardization vs. Flexibility
We aligned with established Canadian cultural taxonomies to ensure interoperability with funders and data-producing institutions. However, we introduced a thematic layer to accommodate emerging or cross-disciplinary practices. This balanced structural consistency with adaptability.
2. Feature Depth vs. Launch Readiness
Advanced capabilities, such as user accounts and expanded contribution workflows, were intentionally deferred. For launch, we prioritized a stable, high-performing search system and validated dataset entries over feature breadth.
3. Ideal Classification vs. Technical Feasibility
Early taxonomy models required refinement once translated into relational SQL logic. Rather than forcing conceptual purity, we adjusted structures to ensure database efficiency, scalable indexing, and predictable filter behavior.
4. Visual Complexity vs. Cognitive Clarity
We deliberately avoided dense dashboards or decorative elements. The interface prioritized metadata hierarchy, comparability, and trust signals to support analytical users.